kgp.py 使用了多種技巧,在你進行 XML 處理時,它們或許能派上用場。第一個就是,利用輸入文檔的結構穩定特征來構建節點緩沖。
一個語法文件定義了一系列的 ref 元素。每個 ref 包含了一個或多個 p 元素,p 元素則可以包含很多不同的東西,包括 xref。對于每個 xref,你都能找到相對應的 ref 元素 (它們具有相同的 id 屬性),然后選擇 ref 元素的子元素之一進行解析。(在下一部分中你將看到是如何進行這種隨機選擇的。)
語法的構建方式如下:先為最小的片段定義 ref 元素,然后使用 xref 定義“包含”第一個 ref 元素的 ref 元素,等等。然后,解析“最大的”引用并跟著 xref 跳來跳去,最后輸出真實的文本。輸出的文本依賴于你每次填充 xref 時所做的 (隨機) 決策,所以每次的輸出都是不同的。
這種方式非常靈活,但是有一個不好的地方:性能。當你找到一個 xref 并需要找到相應的 ref 元素時,會遇到一個問題。xref 有 id 屬性,而你要找擁有相同 id 屬性的 ref 元素,但是沒有簡單的方式做到這件事。較慢的方式是每次獲取所有 ref 元素的完整列表,然后手動遍歷并檢視每一個 id 屬性。較快的方式是只做一次,然后以字典形式構建一個緩沖。
例 10.14. loadGrammar
def loadGrammar(self, grammar):
self.grammar = self._load(grammar)
self.refs = {} 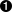 for ref in self.grammar.getElementsByTagName("ref"):
for ref in self.grammar.getElementsByTagName("ref"): 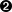 self.refs[ref.attributes["id"].value] = ref
self.refs[ref.attributes["id"].value] = ref 

| 從創建一個空字典 self.refs 開始。 | |
| 正如你在第 9.5 節 “搜索元素”中看到的,getElementsByTagName 返回所有特定名稱元素的一個列表。你可以很容易地得到所有 ref 元素的一個列表,然后遍歷這個列表。 | |
| 正如你在第 9.6 節 “訪問元素屬性”中看到的,使用標準的字典語法,你可以通過名稱來訪問個別元素。所以,self.refs 字典的鍵將是每個 ref 元素的 id 屬性值。 | |
| self.refs 字典的值將是 ref 元素本身。如你在第 9.3 節 “XML 解析”中看到的,已解析 XML 文檔中的每個元素、節點、注釋和文本片段都是一個對象。 |
只要構建了這個緩沖,無論何時你遇到一個 xref 并且需要找到具有相同 id 屬性的 ref 元素,都只需在 self.refs 中查找它。
例 10.15. 使用 ref 元素緩沖
def do_xref(self, node):
id = node.attributes["id"].value
self.parse(self.randomChildElement(self.refs[id]))你將在下一部分探究 randomChildElement 函數。